To help people who are starting up with the use of Spark service and/or its
integration in SWAN, we have been happy to run introductory short classes on
a yearly basis.
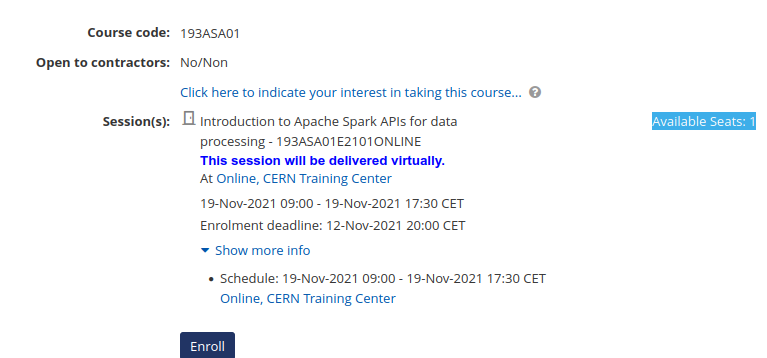
Please note that the next session of the course “Introduction to Apache
Spark APIs for data processing” will take place online on November 19th.
The course is an introduction and overview with practical examples to the
concepts, methods, and tools necessary to be effective in architecting and
developing solutions using Apache Spark for data processing at scale.
The format is lecture style with demos + hands-on exercises using Jupyter
notebooks on SWAN and the Spark service at CERN.
Looking at the link, do I understand correctly there will be the possibility to also follow the course remotely? How many places are available? (there seem to be just one “seat” from the description…)
The training will be only virtual, which means you can follow it remotely.
It seems that at the moment all the slots have been reserved, but if you show your interest adding yourself to the wait list you will be notified in case more slots are open or if there is a new session.