I am using spark clusters (k8s) through the PyRDF module and I am encountering a really interesting issue that I think I never heard before…
As I said, I am using the PyRDF module (which is a wrapper of ROOT RDataFrames) and I tried to use the recently supported AsNumpy() method to transform a ROOT::RDataFrame into a dictionary of numpy arrays.
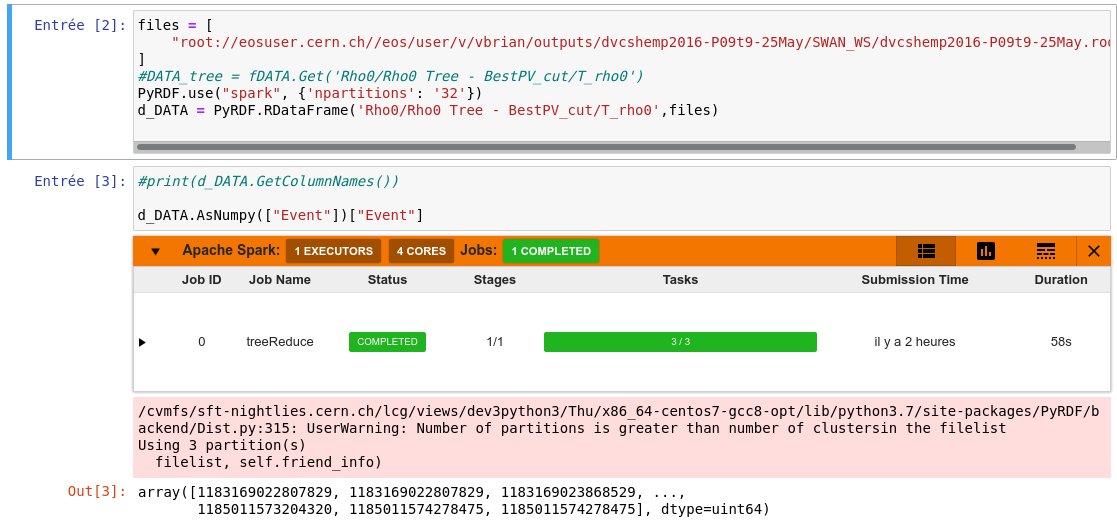
To mention it, the latter method AsNumpy() both for RDataFrames and PyRDF dataframes, locally AND on spark backend (see my following simplest example)
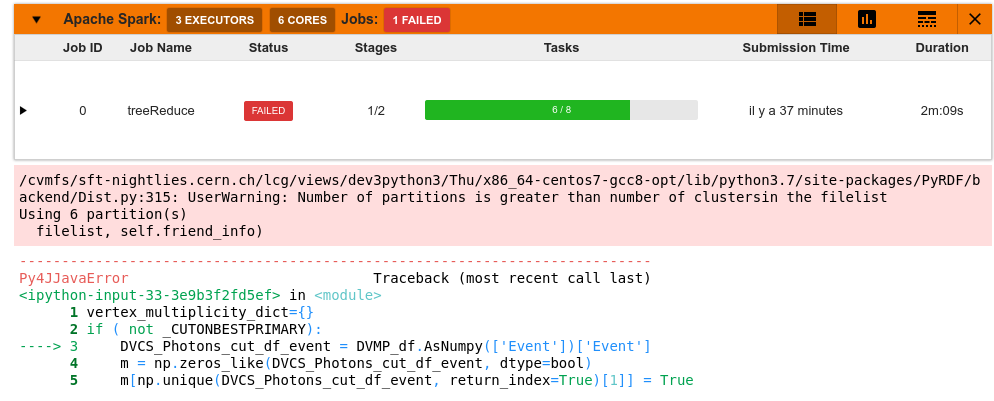
I am actually really happy of that recent update, so I tried to extend this to my actual analysis, with much more filters, but doing the same method at one point (following plot)
Weirdly, you see that some jobs succeed, but also some don’t, making me then unhappy. And I honestly do not get why some work and why some don’t, maybe the individual jobs worked but not the collector of the results, I don’t know.
I would be glad to provide a simplest notebook example of this, but I am not sure I could easily do that. Can it be that my dataframe graph is too complicated / too long to run, and that jobs are crashing ?
I indeed remark that my notebook always take a lot of time to run because of a huge dataframe graph I have to admit…
As you pointed out, Spark is failing in completing some jobs but unfortunately that can be due to many causes. To make sure it’s not related to PyRDF, could you provide a smaller reproducer? It would even be helpful if you could show me how you are extending the AsNumpy() functionality in your library.
Dear Vincenzo,
Thanks for your fast reply, and for sure : here is a simple reproducer (I actually showed you in the previous thread the success of the output)
import PyRDF
import ROOT
# Configure PyRDF to run on Spark splitting the dataset into 32 partitions (defines parallelism)
PyRDF.use("spark", {'npartitions': '32'})
# Create dataframe from NanoAOD files
files = [
"root://eospublic.cern.ch//eos/root-eos/cms_opendata_2012_nanoaod/Run2012B_DoubleMuParked.root",
"root://eospublic.cern.ch//eos/root-eos/cms_opendata_2012_nanoaod/Run2012C_DoubleMuParked.root"
]
df = PyRDF.RDataFrame("Events", files)
df_2mu = df.Filter("nMuon == 2", "Events with exactly two muons");
print(df_2mu.AsNumpy(["nMuon"])["nMuon"])
This is using a dataframe from an example in SWAN but it also works using my own root file and even choosing a column of c++ type unsigned long long int.
As for what/how I am doing in my library, it si quite complicated and personal I think to be posted here I would prefer to show/describe you explicitely via swan share and a small vidyo meeting whenever you are available. Then I could describe you how I am doing stuff and I am sure you will have some hints of what is fishy there (even though it worked at a time…). We can discuss this in private message if you wish, and I will post here after investigations some solutions for other people then.
Hi @vbrian,
Yes indeed the simple example runs straight away, I saw your code in the initial post but actually what I was looking for was something closer to what you are actually doing in your application.
I understand that may not be simple enough to be posted here, so I would gladly fix a vidyo call with you next week at a time that suits you.
That is very kind of you, I appreciate a lot.
Is Tuesday morning ok for you ? If we can say around 9h30 and in my or your vidyo Room I do not care (let’s say mine to fix ideas, and we keep contact to meet then )
BTW Prasanth is just telling me that there are python/C++ errors like break seg fault and so on. I am sending this to you by mail ; not sure though if it is PyRDF related…
EDIT: accessible also there /afs/cern.ch/user/p/pkothuri/public/spark.vbrian.log

 )
)