I am currently using the PyRDF module to run RDataFrames with spark. Regarding its configuration for spark backend, I ask for 40 partitions, and regarding spark I added the following lines to my notebook.
Spark cluster you use, works with Dynamic Allocation enabled by default - Configuration - Spark 3.5.0 Documentation, plus with “Min Resources Queues - each user is guaranteed to get 3 executors at minimum and rest is opportunistic”
It means, that spark.executor.instances parameter will be just used initially for burst, but then it will downscale/upscale number of executors according to your estimated by spark needs (based on dynamics of your tasks). It is to ensure you efficiently use resources and downscale when you don’t use.
What we usually recommend is that you don’t change these defaults. For development, please use dynamic allocation with low default. When you have your workload ready, and want to increase the scale, you can adjust spark.dynamicAllocation.minExecutors to e.g. 10 executors (as you know you will have 40 cores → 10 exec).
Please however take note that “Min Queues” will penalise you (kill your executors) if other users want resources and you don’t work with default dynamic allocation.
I contact you because I have encountered for some time a “weird” behaviour of my spark exectuor/cores number. As your previous message, I modified the following parameters
I know I should not change the default values, however when I launch my spark jobs I always see something like 3 executors and 6 cores, so that my jobs always take too long to my taste (~30-45 minutes) which decrease the interactive interest of SWAN… I guess that these values are adapted by kubernetes dynamically to my spark needs, but they seem to be more important than what estimated to me…
What should I do ?
You need to specify these BEFORE spark starts. Click “Spark” star button, input “spark.dynamicAllocation.minExecutors”, press enter, input e.g. “8”, click “Connect” button.
Indeed it works. Thanks for the tip ! Also I just found I have been wrong in my PyRDF parameters to use spark, I had to tune a parameter to make more partitions from my dataframe in order to use better the resources I ask to spark.
Here is the way to do it for the PyRDF module if anyone uses it also:
PyRDF.use(“spark”, {‘npartitions’: ‘32’})
NB: just a small remark, sometimes the spark monitor does not appear right under the cell but somewhere randomly in the notebook Anyway, thanks a lot again !
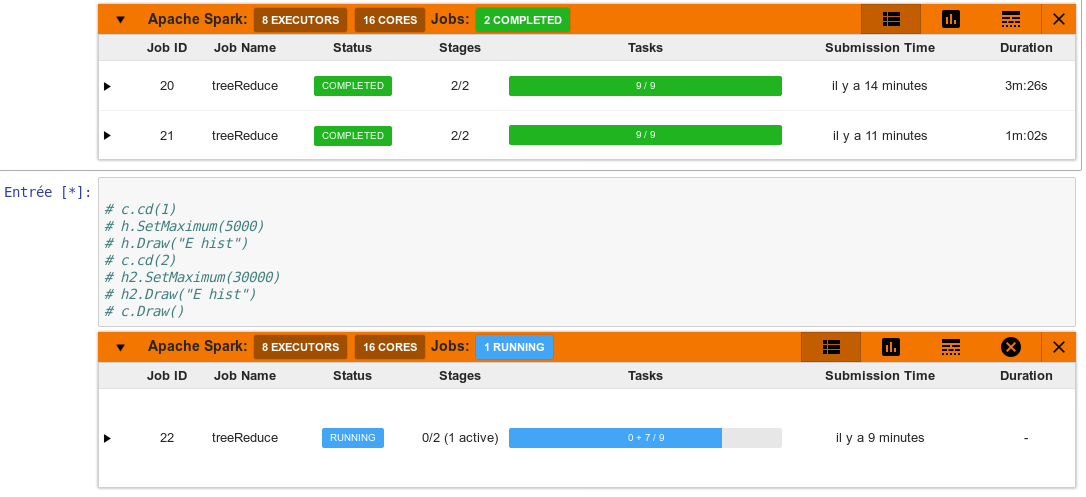
For isntance for the first line, I can see that my jobs were submitted 14 minutes ago, but taking only 3min26 to process. If I may guess, that means that my job takes 11min pending in the queue. May I ask why so much time ? (Are there too many people using spark ?)
Submission time is relative to moment you look at it. So if duration was 3m26s, and submission was 14 minutes ago, your job finished 11min ago.
If you see “X executors”, and X>0 it means you got allocated the resources for you. Time it takes X->Y is the time you been waiting for a resource, which usually is in seconds. You however are always granted a minimum resources, which is 3 executors. We will try to scale our cluster to ensure at peak usage each user will get at least 3 executors, and the rest is opportunistic and decided by dynamic allocation.